目前自己做了个捕熊陷阱的demo,作用是总结了一套基本架构出来.证明兵棋AI能够使用深度学习来实现.接下来具体展开谈谈.
1:架构方面
目前开发了一套伸缩性较强的最基本的架构出来,后面的目标则是一边使用一边开发新架构,尽可能的让非程序员也能使用这套架构开发兵棋,所以接下来的开发工作需要设计者深度参与,学习游戏引擎的基本使用(只要会改改数值,切切图啥的,不需要写代码).
2,AI
2.1:可行性
游戏AI用的是多智能体强化学习的一种算法:MA2C,目前测试出来的结果就是会进攻,站点,防守.基本上会玩,后面再改进一下还能提升能力.目前有个问题就是,捕熊陷阱的美军规则设定前三个回合防守,后三个回合撤退,也就是目标会发生变化,导致训练效果不好,这点后面再想办法改进.总之,目前证明小棋使用深度学习是没问题.
2.2:性能
现在我是用的是第三方的深度学习库,这个我准备后面自己写个简单的库出来,进行一定程度的优化,主要是优化包体大小,第三方库打包完了几百M,太大了.
最后是钱的问题,刚起步,肯定搞不了几个钱- -,想赚钱的话,是个长期工作…
总的来说,程序是没问题,就看有没有佬来帮忙设计了,速来 
1 个赞
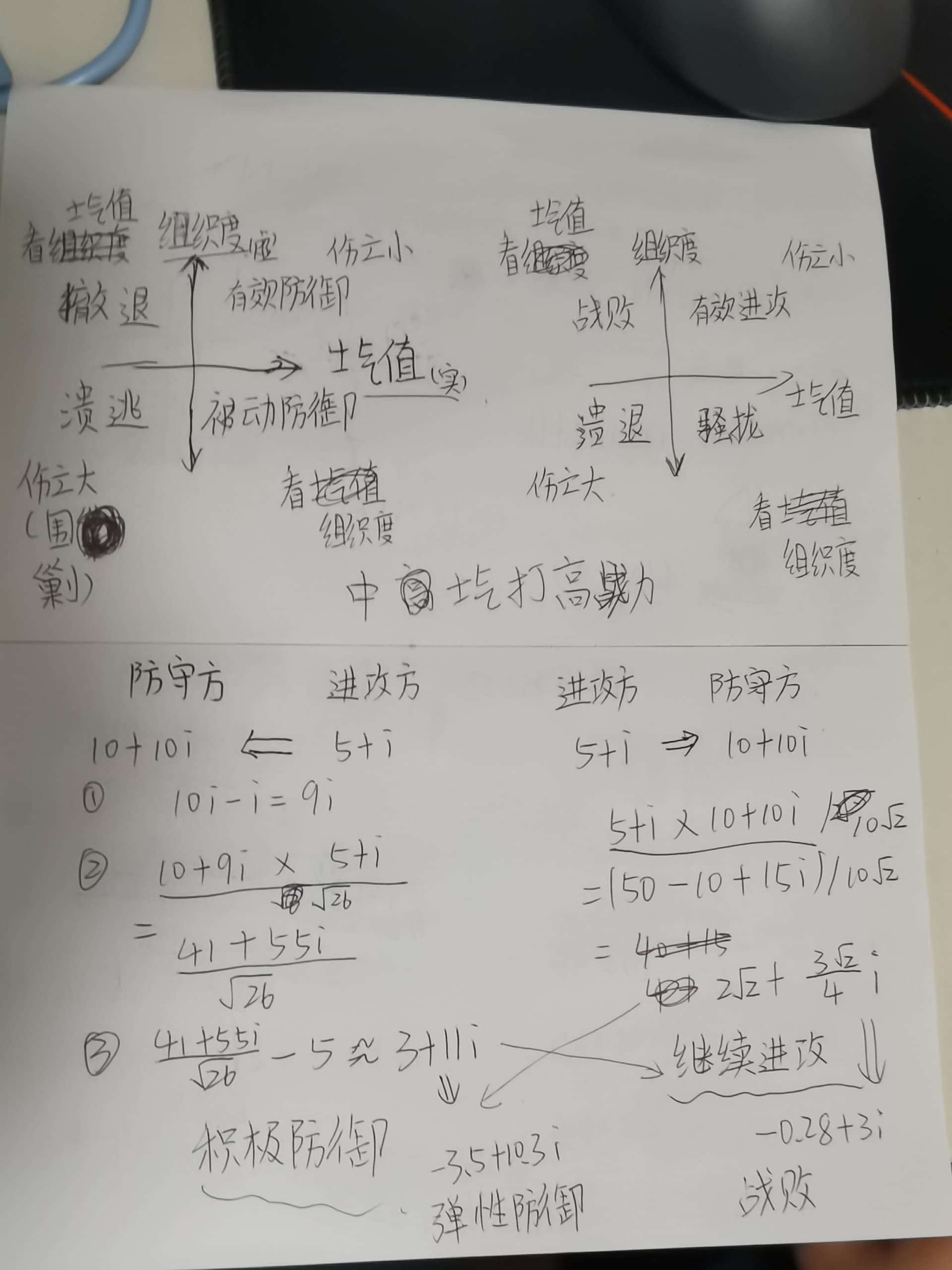
代入虚数,用复数形式计算可以把组织度和士气值联系起来,甚至可以模拟游击战,不知道电脑弄不弄得了,电脑可以微分计算
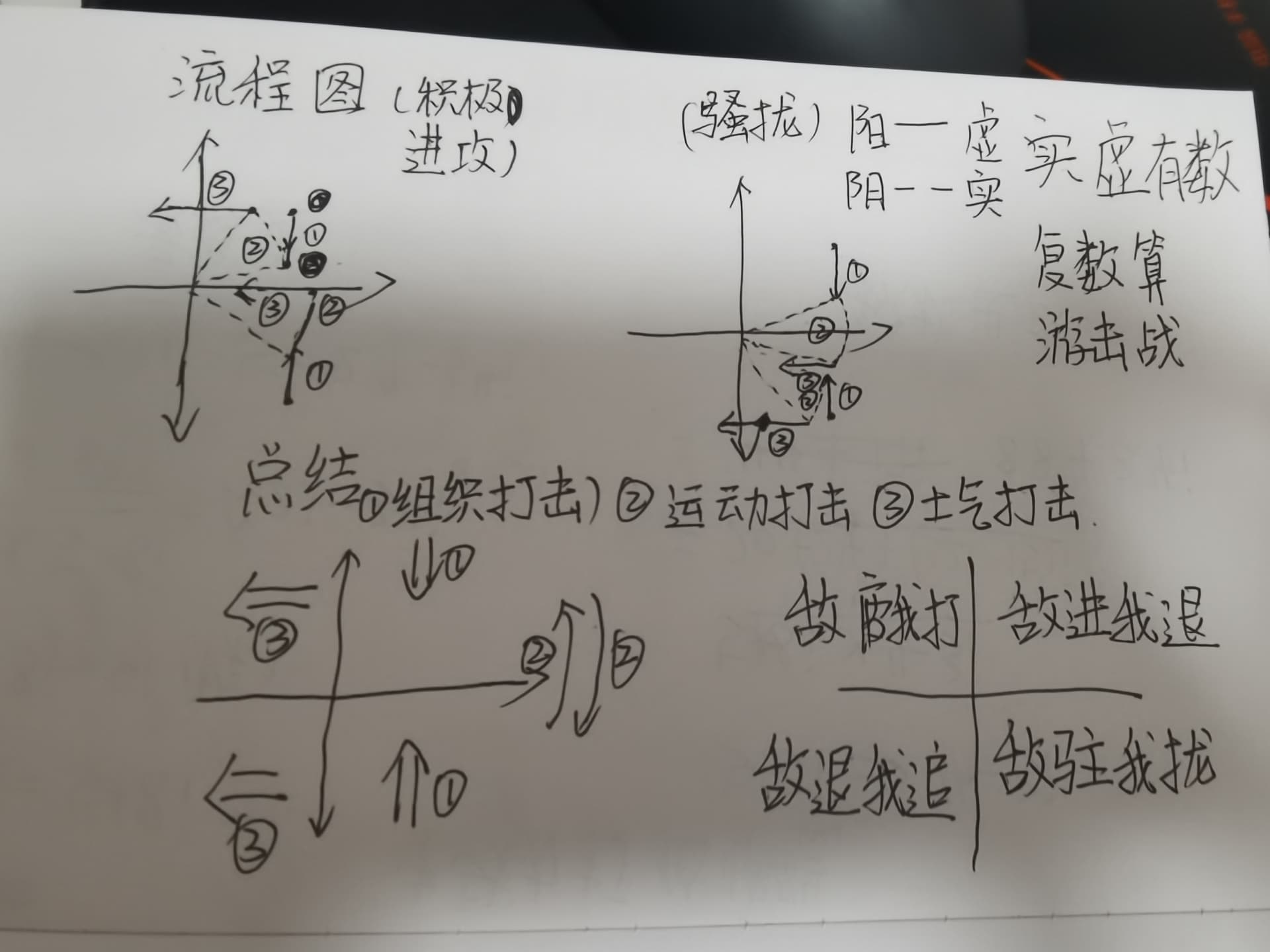
很有意思,也是可实现的,基本上都是向量运算.就是流程得请教一下,第一张图的③之后的-3.5+10.3i是咋算的,还有连线的弹性防御和继续进攻是什么意思
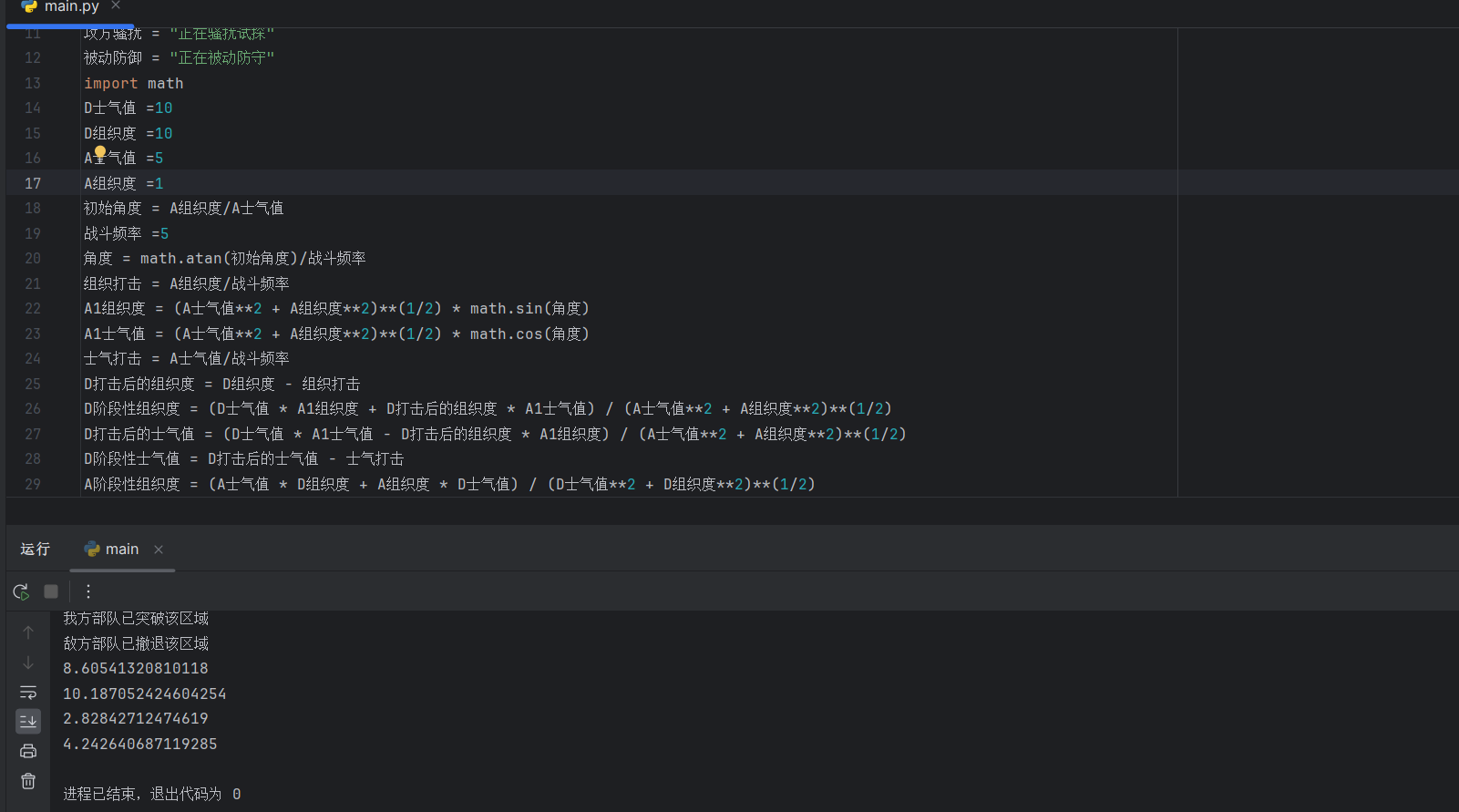
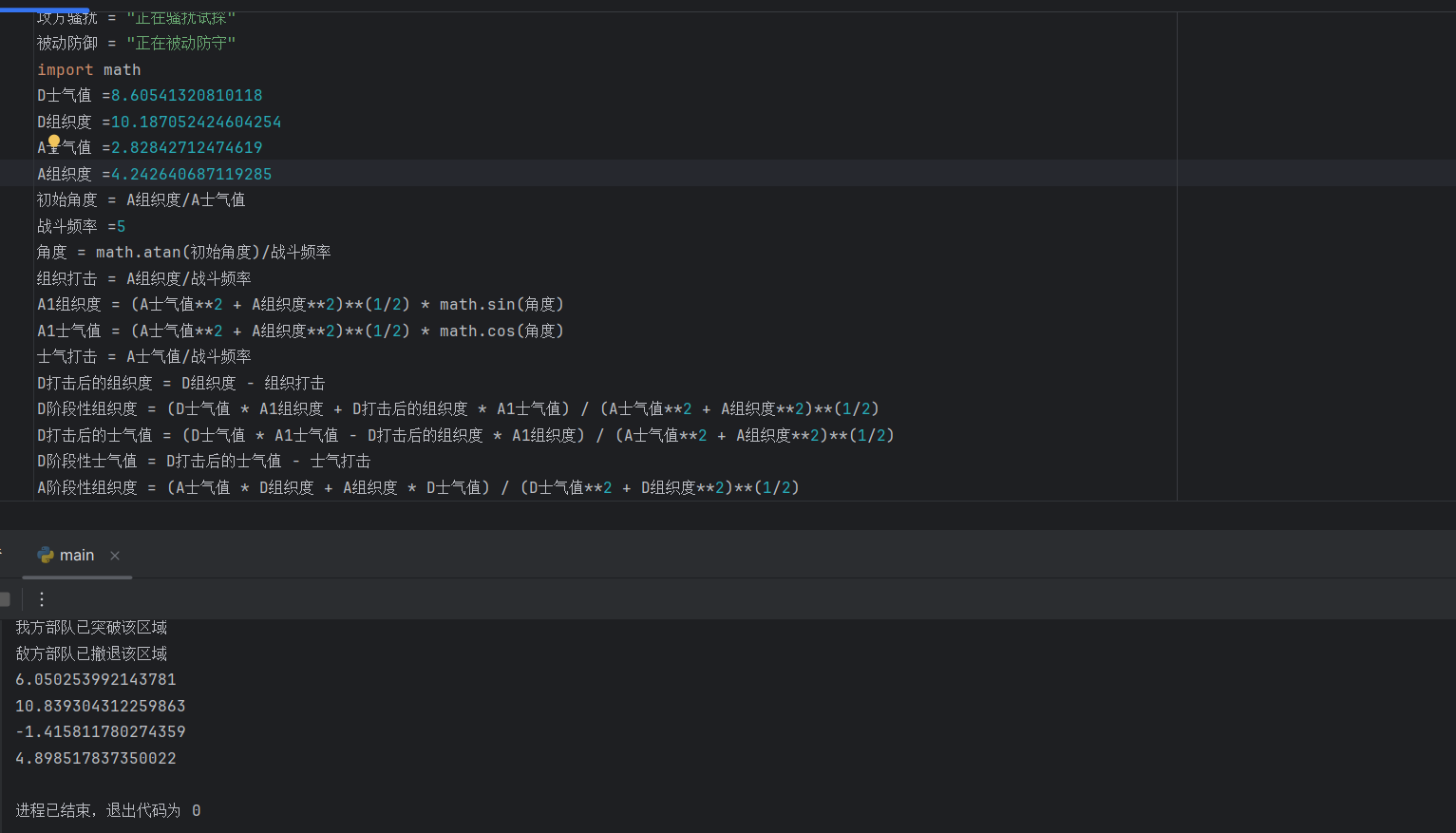
就是按图三的三个打击阶段,组织打击、运动打击和士气打击,具体过程可以看我写的代码
其中战斗频率是指一场战役中的战斗次数,也就是你前面问的弹性防御和继续进攻的来源,如果是电子兵棋,战斗频率就相当于微分。。而且频率跟武器、载具和战术有关,坦克就会减少频率以加强战斗强度。而不止只是高频率的堑壕战
 感觉问题是战斗频率该怎么设置,变量很多.
感觉问题是战斗频率该怎么设置,变量很多.
另外老哥会python可以去学godot,自带类似python的脚本语言,也支持复杂的C#,功能上做兵棋绰绰有余,也比较适合入门.要是有兴趣也可以来跟我搞事情 
你好,我愿意一起设计电子兵棋的,我设计了一些vassal上的小桌游自娱自乐,但是发现自己设计的规则过于复杂也难以计算,十分希望能让计算机去处理。QQ我加不上,一直显示你的好友申请问题错误
哈哈哈是的vassal自带编程,  但是我还没弄明白具体咋搞,只是在vassal新建模组后按着自己学到的玩到的一些规则加上自己的愚见加点自己做的算子,加点卡牌池和地图做个简单的桌游这样子,我知道有的模组甚至可以自动计算推演数据,真的很牛(这么看我属于美工不属于做了兵棋。。。)
但是我还没弄明白具体咋搞,只是在vassal新建模组后按着自己学到的玩到的一些规则加上自己的愚见加点自己做的算子,加点卡牌池和地图做个简单的桌游这样子,我知道有的模组甚至可以自动计算推演数据,真的很牛(这么看我属于美工不属于做了兵棋。。。)